
本次活動將重點聚焦高性能計算(HPC)與人工智能(AI)在制造行業(yè)的深度融合,探索數(shù)字化轉(zhuǎn)型中的智能制造新趨勢。


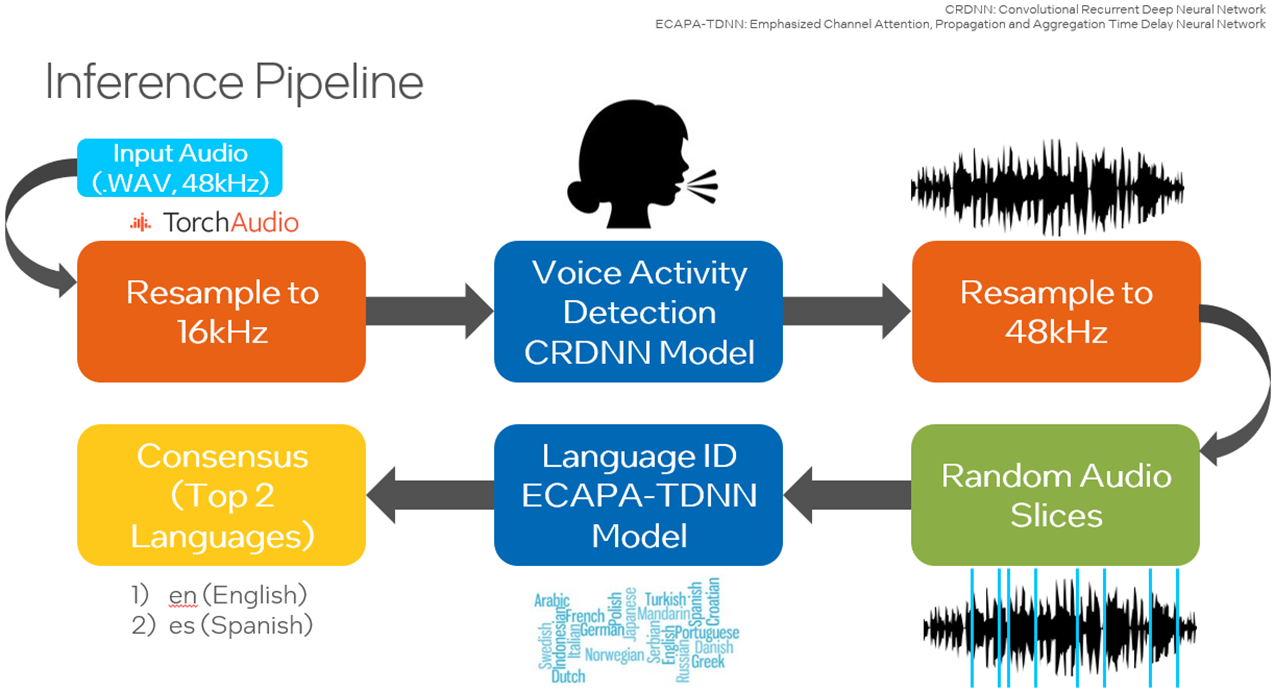
語言識別是從多個音頻輸入樣本中識別主要語言的過程。在自然語言處理(NLP)中,語言識別是一個重要的問題,也是一個具有挑戰(zhàn)性的問題。有許多與語言相關(guān)的任務(wù),例如在手機(jī)上輸入文本、查找您喜歡的新聞文章或發(fā)現(xiàn)您可能遇到的問題的答案。所有這些任務(wù)都由NLP模型提供支持。為了決定在特定時間點調(diào)用哪個模型,我們必須執(zhí)行語言識別。
本文介紹了使用英特爾? PyTorch 擴(kuò)展(針對英特爾處理器進(jìn)行了優(yōu)化的 PyTorch AI 框架的一個版本)和英特爾??神經(jīng)壓縮器(一種在不犧牲準(zhǔn)確性的情況下加速人工智能推理的工具)進(jìn)行語言識別的深入解決方案和代碼示例。
該代碼示例演示了如何使用擁抱人臉語音大腦* 工具套件訓(xùn)練模型以執(zhí)行語言識別,并使用英特爾?人工智能分析工具包 (AI Kit) 對其進(jìn)行優(yōu)化。用戶可以修改代碼示例,并使用通用語音數(shù)據(jù)集識別多達(dá) 93 種語言。
語言識別方法
在建議的解決方案中,用戶將使用英特爾人工智能分析工具包容器環(huán)境來訓(xùn)練模型,并利用英特爾優(yōu)化的 PyTorch 庫執(zhí)行推理。還有一個選項可以使用英特爾神經(jīng)壓縮器量化訓(xùn)練的模型,以加快推理速度。
數(shù)據(jù)
對于此代碼示例,將使用通用語音數(shù)據(jù)集,特別是日語和瑞典語的通用語音語料庫 11.0。該數(shù)據(jù)集用于訓(xùn)練強(qiáng)調(diào)通道注意力、傳播和聚合時間延遲神經(jīng)網(wǎng)絡(luò) (ECAPA-TDNN),該網(wǎng)絡(luò)使用 Hugging Face SpeechBrain 庫實現(xiàn)。延時神經(jīng)網(wǎng)絡(luò) (TDNN),又名一維卷積神經(jīng)網(wǎng)絡(luò) (1D CNN),是多層人工神經(jīng)網(wǎng)絡(luò)架構(gòu),用于對網(wǎng)絡(luò)每一層具有移位不變性和模型上下文的模式進(jìn)行分類。ECAPA-TDNN是一種新的基于TDNN的揚(yáng)聲器嵌入提取器,用于揚(yáng)聲器驗證;它建立在原始的 X-Vector 架構(gòu)之上,更加強(qiáng)調(diào)信道注意力、傳播和聚合。
實現(xiàn)
下載 Common Voice 數(shù)據(jù)集后,通過將 MP3 文件轉(zhuǎn)換為 WAV 格式來對數(shù)據(jù)進(jìn)行預(yù)處理,以避免信息丟失,并分為訓(xùn)練集、驗證集和測試集。
使用Hugging Face SpeechBrain庫使用Common Voice數(shù)據(jù)集重新訓(xùn)練預(yù)訓(xùn)練的VoxLingua107模型,以專注于感興趣的語言。VoxLingua107 是一個語音數(shù)據(jù)集,用于訓(xùn)練口語識別模型,這些模型可以很好地處理真實世界和不同的語音數(shù)據(jù)。此數(shù)據(jù)集包含 107 種語言的數(shù)據(jù)。默認(rèn)情況下,使用日語和瑞典語,并且可以包含更多語言。然后,此模型用于對測試數(shù)據(jù)集或用戶指定的數(shù)據(jù)集進(jìn)行推理。此外,還有一個選項可以利用SpeechBrain的語音活動檢測(VAD),在隨機(jī)選擇樣本作為模型的輸入之前,僅從音頻文件中提取和組合語音片段。此鏈接提供了執(zhí)行 VAD 所需的所有工具。為了提高性能,用戶可以使用英特爾神經(jīng)壓縮器將訓(xùn)練好的模型量化為整數(shù) 8 (INT8),以減少延遲。
訓(xùn)練
訓(xùn)練腳本的副本將添加到當(dāng)前工作目錄中,包括 - 用于創(chuàng)建 WebDataset 分片,- 執(zhí)行實際訓(xùn)練過程,以及 - 配置訓(xùn)練選項。用于創(chuàng)建 Web數(shù)據(jù)集分片和 YAML 文件的腳本經(jīng)過修補(bǔ),可與此代碼示例選擇的兩種語言配合使用。create_wds_shards.pytrain.pytrain_ecapa.yaml
在數(shù)據(jù)預(yù)處理階段,執(zhí)行腳本隨機(jī)選擇指定數(shù)量的樣本,將輸入從MP3轉(zhuǎn)換為WAV格式。在這里,這些樣本中有 80% 將用于訓(xùn)練,10% 用于驗證,10% 用于測試。建議至少 2000 個樣本作為輸入樣本數(shù),并且是默認(rèn)值。prepareAllCommonVoice.py
在下一步中,將從訓(xùn)練和驗證數(shù)據(jù)集創(chuàng)建 WebDataset 分片。這會將音頻文件存儲為 tar 文件,允許為大規(guī)模深度學(xué)習(xí)編寫純順序 I/O 管道,以便從本地存儲實現(xiàn)高 I/O 速率——與隨機(jī)訪問相比,大約快 3-10 倍。
用戶將修改 YAML 文件。這包括設(shè)置 WebDataset 分片的最大數(shù)量值、將神經(jīng)元輸出為感興趣的語言數(shù)量、要在整個數(shù)據(jù)集上訓(xùn)練的紀(jì)元數(shù)以及批大小。如果在運(yùn)行訓(xùn)練腳本時 CPU 或 GPU 內(nèi)存不足,則應(yīng)減小批大小。
在此代碼示例中,將使用 CPU 執(zhí)行訓(xùn)練腳本。運(yùn)行腳本時,“cpu”將作為輸入?yún)?shù)傳遞。中定義的配置也作為參數(shù)傳遞。train_ecapa.yaml
運(yùn)行腳本以訓(xùn)練模型的命令是:
python train.py train_ecapa.yaml --device "cpu"
將來,培訓(xùn)腳本 train.py 將設(shè)計為適用于英特爾? GPU,如英特爾?數(shù)據(jù)中心 GPU Flex 系列、英特爾數(shù)據(jù)中心 GPU Max 系列和英特爾 Arc A 系列,并更新了英特爾??擴(kuò)展 PyTorch。
A 系列,并更新了英特爾??擴(kuò)展 PyTorch。
運(yùn)行訓(xùn)練腳本以了解如何訓(xùn)練模型和執(zhí)行訓(xùn)練腳本。建議將此遷移學(xué)習(xí)應(yīng)用使用第四代英特爾至強(qiáng)?可擴(kuò)展處理器,因為它通過其英特爾高級矩陣擴(kuò)展(英特爾??? AMX)指令集提高了性能。
訓(xùn)練后,檢查點文件可用。這些文件用于加載模型以進(jìn)行推理。
推理
運(yùn)行推理之前的關(guān)鍵步驟是修補(bǔ) SpeechBrain 庫的預(yù)訓(xùn)練文件,以便可以運(yùn)行 PyTorch TorchScript* 以改善運(yùn)行時。TorchScript 要求模型的輸出只是張量。interfaces.py
用戶可以選擇使用 Common Voice 中的測試集或他們自己的 WAV 格式自定義數(shù)據(jù)運(yùn)行推理。以下是推理腳本 () 可用于運(yùn)行的選項:inference_custom.py and inference_commonVoice.py
| 輸入選項 | 描述 |
| -p | 指定數(shù)據(jù)路徑。 |
| -d | 指定波采樣的持續(xù)時間。默認(rèn)值為 3。 |
| -s | 指定采樣波的大小,默認(rèn)值為 100。 |
| --瓦德 | (僅限“inference_custom.py”)啟用 VAD 模型以檢測活動語音。VAD 選項將識別音頻文件中的語音片段,并構(gòu)造一個僅包含語音片段的新.wav文件。這提高了用作語言識別模型輸入的語音數(shù)據(jù)的質(zhì)量。 |
| --易派克 | 使用英特爾擴(kuò)展 PyTorch 優(yōu)化運(yùn)行推理。此選項會將優(yōu)化應(yīng)用于預(yù)訓(xùn)練模型。使用此選項應(yīng)可提高與延遲相關(guān)的性能。 |
| --ground_truth_compare | (僅限“inference_custom.py”)啟用預(yù)測標(biāo)簽與地面真實值的比較。 |
| --詳細(xì) | 打印其他調(diào)試信息,例如延遲。 |
必須指定數(shù)據(jù)的路徑。默認(rèn)情況下,將從原始音頻文件中隨機(jī)選擇 100 個 3 秒的音頻樣本,并用作語言識別模型的輸入。
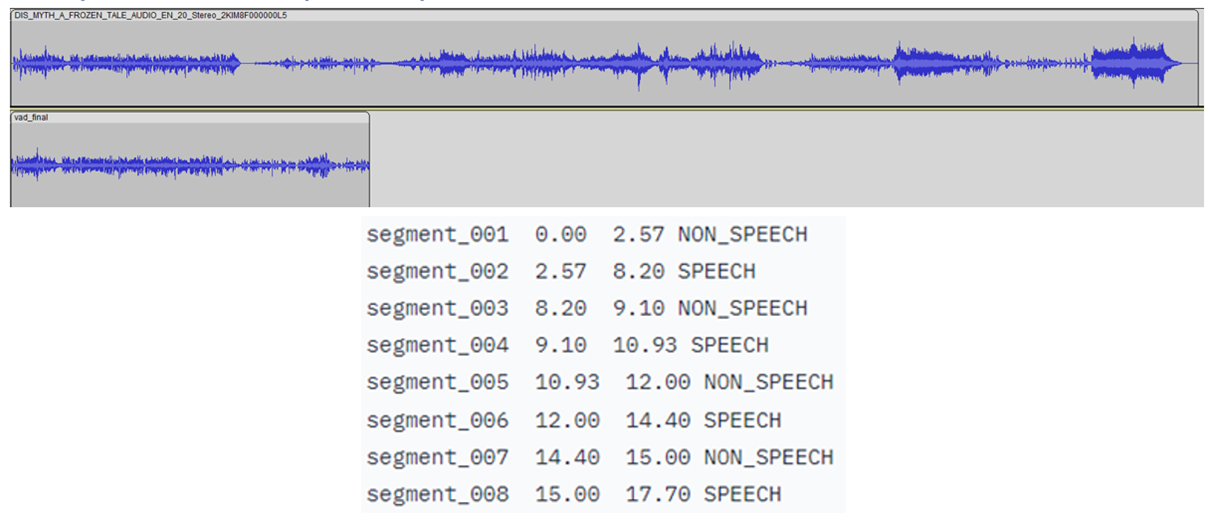
在LibriParty數(shù)據(jù)集上預(yù)訓(xùn)練的小型卷積遞歸深度神經(jīng)網(wǎng)絡(luò)(CRDNN)用于處理音頻樣本并輸出檢測到語音活動的片段。這可以通過選項在推理中使用。--vad
如下圖所示,將檢測到語音的時間戳是從 CRDNN 模型傳送的,這些時間戳用于構(gòu)建僅包含語音的較短的新音頻文件。從這個新的音頻文件中采樣將更好地預(yù)測所說的主要語言。
自行運(yùn)行推理腳本。運(yùn)行推理的示例命令:
python inference_custom.py -p data_custom -d 3 -s 50 --vad
這將對您提供的位于data_custom文件夾中的數(shù)據(jù)運(yùn)行推理。此命令使用語音活動檢測對 50 個隨機(jī)選擇的 3 秒音頻樣本執(zhí)行推理。
如果要運(yùn)行其他語言的代碼示例,請下載其他語言的通用語音語料庫 11.0 數(shù)據(jù)集。
針對 PYTORCH 和英特爾神經(jīng)壓縮器的英特爾擴(kuò)展優(yōu)化
PyTorch
英特爾擴(kuò)展擴(kuò)展了 PyTorch 的最新功能和優(yōu)化,從而進(jìn)一步提升了英特爾硬件的性能。查看如何安裝 PyTorch 的英特爾擴(kuò)展。擴(kuò)展可以作為 Python 模塊加載,也可以作為C++庫鏈接。Python 用戶可以通過導(dǎo)入 .intel_extension_for_pytorch
- CPU 教程提供了有關(guān)適用于英特爾 CPU 的 PyTorch 英特爾擴(kuò)展的詳細(xì)信息。源代碼可在主分支處獲得。
- GPU 教程提供了有關(guān)適用于英特爾 GPU 的 PyTorch 英特爾擴(kuò)展的詳細(xì)信息。源代碼可在 xpu-master 分支獲得。
要使用英特爾 PyTorch 擴(kuò)展優(yōu)化模型以進(jìn)行推理,可以傳入該選項。使用插件優(yōu)化模型。TorchScript 加快了推理速度,因為 PyTorch 以圖形模式運(yùn)行。使用此優(yōu)化運(yùn)行的命令是:--ipex
python inference_custom.py -p data_custom -d 3 -s 50 --vad --ipex --verbose
注意:需要該選項才能查看延遲測量值。--verbose
自動混合精度(如 bfloat16 (BF16) 支持)將在代碼示例的未來版本中添加。
英特爾神經(jīng)壓縮器
這是一個在 CPU 或 GPU 上運(yùn)行的開源 Python 庫,它:
- 執(zhí)行模型量化,以減小模型大小并提高深度學(xué)習(xí)推理的部署速度。
- 跨多個深度學(xué)習(xí)框架自動執(zhí)行常用方法,例如量化、壓縮、修剪和知識蒸餾。
- 是 AI 套件的一部分
通過在傳入模型和驗證數(shù)據(jù)集的路徑的同時運(yùn)行腳本,可以將模型從 float32 (FP32) 精度量化為整數(shù) 8 (INT8)。以下代碼可用于加載此 INT8 模型以進(jìn)行推理:quantize_model.py
from neural_compressor.utils.pytorch import load
model_int8 = load("./lang_id_commonvoice_model_INT8", self.language_id)
signal = self.language_id.load_audio(data_path)
prediction = self.model_int8(signal)
請注意,加載量化模型時需要原始模型。使用 FP32 量化訓(xùn)練模型到 INT8 的命令是:quantize_model.py
python quantize_model.py -p ./lang_id_commonvoice_model -datapath $COMMON_VOICE_PATH/commonVoiceData/commonVoice/dev
以上是關(guān)于使用 PyTorch 構(gòu)建端到端 AI 解決方案的一些介紹。
- END -
我們有個AI研發(fā)云平臺
集成多種AI應(yīng)用,大量任務(wù)多節(jié)點并行
應(yīng)對短時間爆發(fā)性需求,連網(wǎng)即用
跑任務(wù)快,原來幾個月甚至幾年,現(xiàn)在只需幾小時
5分鐘快速上手,拖拉點選可視化界面,無需代碼
支持高級用戶直接在云端創(chuàng)建集群
掃碼免費(fèi)試用,送200元體驗金,入股不虧~

更多電子書歡迎掃碼關(guān)注小F(ID:iamfastone)獲取
你也許想了解具體的落地場景:
王者帶飛LeDock!開箱即用&一鍵定位分子庫+全流程自動化,3.5小時完成20萬分子對接
這樣跑COMSOL,是不是就可以發(fā)Nature了
Auto-Scale這支仙女棒如何大幅提升Virtuoso仿真效率?
1分鐘告訴你用MOE模擬200000個分子要花多少錢
LS-DYNA求解效率深度測評 │ 六種規(guī)模,本地VS云端5種不同硬件配置
揭秘20000個VCS任務(wù)背后的“搬桌子”系列故事
155個GPU!多云場景下的Amber自由能計算
怎么把需要45天的突發(fā)性Fluent仿真計算縮短到4天之內(nèi)?
5000核大規(guī)模OPC上云,效率提升53倍
提速2920倍!用AutoDock Vina對接2800萬個分子
從4天到1.75小時,如何讓Bladed仿真效率提升55倍?
從30天到17小時,如何讓HSPICE仿真效率提升42倍?
關(guān)于為應(yīng)用定義的云平臺:
當(dāng)仿真外包成為過氣網(wǎng)紅后…
和28家業(yè)界大佬排排坐是一種怎樣的體驗?
這一屆科研計算人趕DDL紅寶書:學(xué)生篇
楊洋組織的“太空營救”中, 那2小時到底發(fā)生了什么?
一次搞懂速石科技三大產(chǎn)品:FCC、FCC-E、FCP
Ansys最新CAE調(diào)研報告找到阻礙仿真效率提升的“元兇”
國內(nèi)超算發(fā)展近40年,終于遇到了一個像樣的對手
幫助CXO解惑上云成本的迷思,看這篇就夠了
花費(fèi)4小時5500美元,速石科技躋身全球超算TOP500

什么是人工智能
雖然在過去數(shù)十年中,人工智能 (AI) 的一些定義不斷出現(xiàn),但 John McCarthy 在 2004 年的論文 中給出了以下定義:“這是制造智能機(jī)器,特別是智能計算機(jī)程序的科學(xué)和工程。 它與使用計算機(jī)了解人類智能的類似任務(wù)有關(guān),但 AI 不必局限于生物可觀察的方法”。
然而,在這個定義出現(xiàn)之前數(shù)十年,人工智能對話的誕生要追溯到艾倫·圖靈 (Alan Turing) 于 1950 年發(fā)表的開創(chuàng)性工作:“計算機(jī)械和智能” 。 在這篇論文中,通常被譽(yù)為“計算機(jī)科學(xué)之父”的圖靈提出了以下問題:“機(jī)器能思考嗎?”由此出發(fā),他提出了著名的“圖靈測試”,由人類審查員嘗試區(qū)分計算機(jī)和人類的文本響應(yīng)。 雖然該測試自發(fā)表之后經(jīng)過了大量的審查,但它仍然是 AI 歷史的重要組成部分,也是一種在哲學(xué)中不斷發(fā)展的概念,因為它利用了有關(guān)語言學(xué)的想法。
Stuart Russell 和 Peter Norvig 隨后發(fā)表了“人工智能:現(xiàn)代方法”,成為 AI 研究的主要教科書之一。 在該書中,他們探討了 AI 的四個潛在目標(biāo)或定義,按照理性以及思維與行動將 AI 與計算機(jī)系統(tǒng)區(qū)分開來:
人類方法:
- 像人類一樣思考的系統(tǒng)
- 像人類一樣行動的系統(tǒng)
理想方法:
- 理性思考的系統(tǒng)
- 理性行動的系統(tǒng)
艾倫·圖靈的定義可歸入“像人類一樣行動的系統(tǒng)”類別。
以最簡單的形式而言,人工智能是結(jié)合了計算機(jī)科學(xué)和強(qiáng)大數(shù)據(jù)集的領(lǐng)域,能夠?qū)崿F(xiàn)問題解決。 它還包括機(jī)器學(xué)習(xí)和深度學(xué)習(xí)等子領(lǐng)域,這些子領(lǐng)域經(jīng)常與人工智能一起提及。 這些學(xué)科由 AI 算法組成,這些算法旨在創(chuàng)建基于輸入數(shù)據(jù)進(jìn)行預(yù)測或分類的專家系統(tǒng)。
目前,仍有許多圍繞 AI 發(fā)展的炒作,市場上任何新技術(shù)的出現(xiàn)都會引發(fā)熱議。 正如Gartner 的炒作周期中所指出的,包括自動駕駛汽車和個人助理在內(nèi)的產(chǎn)品創(chuàng)新遵循:“創(chuàng)新的典型發(fā)展進(jìn)程,從超高熱情到幻想破滅期,最終了解創(chuàng)新在市場或領(lǐng)域中的相關(guān)性和作用”。正如 Lex Fridman 在其 2019 年的 MIT 講座中所指出的那樣,我們正處于泡沫式期望的顛峰,逐漸接近幻滅槽。
人工智能的類型 - 弱 AI 與強(qiáng) AI
弱 AI 也稱為狹義的 AI 或人工狹義智能 (ANI),是經(jīng)過訓(xùn)練的 AI,專注于執(zhí)行特定任務(wù)。 弱 AI 推動了目前我們周圍的大部分 AI。“范圍窄”可能是此類 AI 更準(zhǔn)確的描述符,因為它其實并不弱,支持一些非常強(qiáng)大的應(yīng)用,如 Apple 的 Siri、Amazon 的 Alexa 以及 IBM Watson 和自主車輛。
強(qiáng) AI 由人工常規(guī)智能 (AGI) 和人工超級智能 (ASI) 組成。 人工常規(guī)智能 (AGI) 是 AI 的一種理論形式,機(jī)器擁有與人類等同的智能;它具有自我意識,能夠解決問題、學(xué)習(xí)和規(guī)劃未來。 人工超級智能 (ASI) 也稱為超級智能,將超越人類大腦的智力和能力。 雖然強(qiáng) AI 仍完全處于理論階段,還沒有實際應(yīng)用的例子,但這并不意味著 AI 研究人員不在探索它的發(fā)展。 ASI 的最佳例子可能來自科幻小說,如 HAL、超人以及《2001 太空漫游》電影中的無賴電腦助手。
深度學(xué)習(xí)與機(jī)器學(xué)習(xí)
由于深度學(xué)習(xí)和機(jī)器學(xué)習(xí)這兩個術(shù)語往往可互換使用,因此必須注兩者之間的細(xì)微差別。 如上所述,深度學(xué)習(xí)和機(jī)器學(xué)習(xí)都是人工智能的子領(lǐng)域,深度學(xué)習(xí)實際上是機(jī)器學(xué)習(xí)的一個子領(lǐng)域。

深度學(xué)習(xí)實際上由神經(jīng)網(wǎng)絡(luò)組成。深度學(xué)習(xí)中的“深度”是指由三層以上組成的神經(jīng)網(wǎng)絡(luò)(包括輸入和輸出)可被視為深度學(xué)習(xí)算法。 這通常如下圖表示:

深度學(xué)習(xí)和機(jī)器學(xué)習(xí)的不同之處在于每個算法如何學(xué)習(xí)。 深度學(xué)習(xí)可以自動執(zhí)行過程中的大部分特征提取,消除某些必需的人工干預(yù),并能夠使用更大的數(shù)據(jù)集。 可將深度學(xué)習(xí)視為“可擴(kuò)展的機(jī)器學(xué)習(xí)”,正如 Lex Fridman 在同一 MIT 講座中所指出的那樣。 常規(guī)的機(jī)器學(xué)習(xí),或叫做"非深度"機(jī)器學(xué)習(xí),更依賴于人工干預(yù)進(jìn)行學(xué)習(xí)。 人類專家確定特征的層次結(jié)構(gòu),以了解數(shù)據(jù)輸入之間的差異,通常需要更多結(jié)構(gòu)化數(shù)據(jù)以用于學(xué)習(xí)。
"深度"機(jī)器學(xué)習(xí)則可以利用標(biāo)簽化的數(shù)據(jù)集,也稱為監(jiān)督式學(xué)習(xí),以確定算法,但不一定必須使用標(biāo)簽化的數(shù)據(jù)集。 它可以原始格式(例如文本、圖像)采集非結(jié)構(gòu)化數(shù)據(jù),并且可以自動確定區(qū)分不同類別數(shù)據(jù)的特征的層次結(jié)構(gòu)。與機(jī)器學(xué)習(xí)不同,它不需要人工干預(yù)數(shù)據(jù)的處理,使我們能夠以更有趣的方式擴(kuò)展機(jī)器學(xué)習(xí)。
人工智能應(yīng)用
目前,AI 系統(tǒng)存在大量的現(xiàn)實應(yīng)用。 下面是一些最常見的示例:
- 語音識別:也稱為自動語音識別 (ASR)、計算機(jī)語音識別或語音到文本,能夠使用自然語言處理 (NLP),將人類語音處理為書面格式。許多移動設(shè)備將語音識別結(jié)合到系統(tǒng)中以進(jìn)行語音搜索,例如: Siri,或提供有關(guān)文本的更多輔助功能,最近比較火的的chatGPT也是。
- 客戶服務(wù):在線聊天機(jī)器人正逐步取代客戶互動中的人工客服。 他們回答各種主題的常見問題 (FAQ) ,例如送貨,或為用戶提供個性化建議,交叉銷售產(chǎn)品,提供用戶尺寸建議,改變了我們對網(wǎng)站和社交媒體中客戶互動的看法。 示例包括具有虛擬客服的電子商務(wù)站點上的聊天機(jī)器人、消息傳遞應(yīng)用(例如 Slack 和 Facebook Messenger)以及虛擬助理和語音助手通常執(zhí)行的任務(wù)。
- 計算機(jī)視覺:該 AI 技術(shù)使計算機(jī)和系統(tǒng)能夠從數(shù)字圖像、視頻和其他可視輸入中獲取有意義的信息,并基于這些輸入采取行動。 這種提供建議的能力將其與圖像識別任務(wù)區(qū)分開來。 計算機(jī)視覺由卷積神經(jīng)網(wǎng)絡(luò)提供支持,應(yīng)用在社交媒體的照片標(biāo)記、醫(yī)療保健中的放射成像以及汽車工業(yè)中的自動駕駛汽車等領(lǐng)域。
- 推薦引擎:AI 算法使用過去的消費(fèi)行為數(shù)據(jù),幫助發(fā)現(xiàn)可用于制定更有效的交叉銷售策略的數(shù)據(jù)趨勢。 這用于在在線零售商的結(jié)帳流程中向客戶提供相關(guān)的附加建議。
- 自動股票交易:旨在用于優(yōu)化股票投資組合,AI 驅(qū)動的高頻交易平臺每天可產(chǎn)生成千上萬個甚至數(shù)以百萬計的交易,無需人工干預(yù)。
人工智能與云計算
人工智能的發(fā)展需要三個重要的基礎(chǔ),分別是數(shù)據(jù)、算力和算法,而云計算是提供算力的重要途徑,所以云計算可以看成是人工智能發(fā)展的基礎(chǔ)。云計算除了能夠為人工智能提供算力支撐之外,云計算也能夠為大數(shù)據(jù)提供數(shù)據(jù)的存儲和計算服務(wù),而大數(shù)據(jù)則是人工智能發(fā)展的另一個重要基礎(chǔ),所以從這個角度來看,云計算對于人工智能的發(fā)展還是比較重要的。當(dāng)然,說到大數(shù)據(jù)還需要提一下物聯(lián)網(wǎng),物聯(lián)網(wǎng)為大數(shù)據(jù)提供了主要的數(shù)據(jù)來源,可以說沒有物聯(lián)網(wǎng)也就不會有大數(shù)據(jù)。
云計算目前正在從IaaS向PaaS和SaaS發(fā)展,這個過程中與人工智能的關(guān)系會越來越密切,主要體現(xiàn)在以下三個方面:
第一:PaaS與人工智能的結(jié)合來完成行業(yè)垂直發(fā)展。當(dāng)前云計算平臺正在全力打造自己的業(yè)務(wù)生態(tài),業(yè)務(wù)生態(tài)其實也是云計算平臺的壁壘,而要想在云計算領(lǐng)域形成一個龐大的壁壘必然需要借助于人工智能技術(shù)。目前云計算平臺開放出來的一部分智能功能就可以直接結(jié)合到行業(yè)應(yīng)用中,這會使得云計算向更多的行業(yè)領(lǐng)域垂直發(fā)展。
第二:SaaS與人工智能的結(jié)合來拓展云計算的應(yīng)用邊界。當(dāng)前終端應(yīng)用的迭代速度越來越快,未來要想實現(xiàn)更快速且穩(wěn)定的迭代,必然需要人工智能技術(shù)的參與。人工智能技術(shù)與云計算的結(jié)合能夠讓SaaS全面拓展自身的應(yīng)用邊界。
第三:云計算與人工智能的結(jié)合降低開發(fā)難度。云計算與人工智能結(jié)合還會有一個明顯的好處,就是降低開發(fā)人員的工作難度,云計算平臺的資源整合能力會在人工智能的支持下,越來越強(qiáng)大。
人工智能的發(fā)展歷史: 大事記
“一臺會思考的機(jī)器”這一構(gòu)想最早可以追溯到古希臘時期。 而自從電子計算技術(shù)問世以來(相對于本文中討論的某些主題而言),人工智能進(jìn)化過程中的重要事件和里程碑包括以下內(nèi)容:
- 1950:艾倫·圖靈發(fā)表了論文“計算機(jī)械和智能”。圖靈因為在二戰(zhàn)期間破譯納粹德國的 ENIGMA 碼而聞名于世。在這篇論文中,他提出了問題“機(jī)器是否可以思考?”并進(jìn)行回答,推出了圖靈測試,用于確定計算機(jī)是否能證明具有與人類相同的智能(或相同智能的結(jié)果)。 自此之后,人們就圖靈測試的價值一直爭論不休。
- 1956:John McCarthy 在達(dá)特茅斯學(xué)院舉辦的首屆 AI 會議上創(chuàng)造了“人工智能”一詞。(McCarthy 繼續(xù)發(fā)明了 Lisp 語言。)同年晚些時候,Allen Newell、J.C.Shaw 和 Herbert Simon 創(chuàng)建了 Logic Theorist,這是有史以來第一個運(yùn)行的 AI 軟件程序。
- 1967:Frank Rosenblatt 構(gòu)建了 Mark 1 Perceptron,這是第一臺基于神經(jīng)網(wǎng)絡(luò)的計算機(jī),它可以通過試錯法不斷學(xué)習(xí)。 就在一年后,Marvin Minsky 和 Seymour Papert 出版了一本名為《感知器》的書,這本書既成為神經(jīng)網(wǎng)絡(luò)領(lǐng)域的標(biāo)志性作品,同時至少在一段時間內(nèi),成為反對未來神經(jīng)網(wǎng)絡(luò)研究項目的論據(jù)。
- 1980 年代:使用反向傳播算法訓(xùn)練自己的神經(jīng)網(wǎng)絡(luò)在 AI 應(yīng)用中廣泛使用。
- 1997:IBM 的深藍(lán)計算機(jī)在國際象棋比賽(和復(fù)賽)中擊敗國際象棋世界冠軍 Garry Kasparov。
- 2011:IBM Watson 在《危險邊緣!》節(jié)目中戰(zhàn)勝冠軍 Ken Jennings 和 Brad Rutter。
- 2015:百度的 Minwa 超級計算機(jī)使用一種稱為卷積神經(jīng)網(wǎng)絡(luò)的特殊深度神經(jīng)網(wǎng)絡(luò)來識別圖像并進(jìn)行分類,其準(zhǔn)確率高于一般的人類。
- 2016:由深度神經(jīng)網(wǎng)絡(luò)支持的 DeepMind 的 AlphaGo 程序在五輪比賽中擊敗了圍棋世界冠軍 Lee Sodol。 考慮到隨著游戲的進(jìn)行,可能的走法非常之多,這一勝利具有重要意義(僅走了四步之后走法就超過 14.5 萬億種!)。 后來,谷歌以四億美元的報價收購了 DeepMind。
- 2021: 由于openA研發(fā)的聊天機(jī)器人程序,于2022年11月30日發(fā)布。ChatGPT是人工智能技術(shù)驅(qū)動的自然語言處理工具,它能夠通過學(xué)習(xí)和理解人類的語言來進(jìn)行對話,還能根據(jù)聊天的上下文進(jìn)行互動,真正像人類一樣來聊天交流, 2023年1月末,ChatGPT的月活用戶已突破1億,成為史上增長最快的消費(fèi)者應(yīng)用。2023年2月7日,微軟宣布推出由ChatGPT支持的最新版本人工智能搜索引擎Bing(必應(yīng))和Edge瀏覽器。微軟CEO表示,“搜索引擎迎來了新時代”。
以上就是速石對人工智能的一些介紹,想了解更多人工智能相關(guān)信息 歡迎掃碼關(guān)注小F(ID:iamfastone)獲取
- END -
我們有個AI研發(fā)云平臺
集成多種AI應(yīng)用,大量任務(wù)多節(jié)點并行
應(yīng)對短時間爆發(fā)性需求,連網(wǎng)即用
跑任務(wù)快,原來幾個月甚至幾年,現(xiàn)在只需幾小時
5分鐘快速上手,拖拉點選可視化界面,無需代碼
支持高級用戶直接在云端創(chuàng)建集群
掃碼免費(fèi)試用,送200元體驗金,入股不虧~

更多電子書歡迎掃碼關(guān)注小F(ID:iamfastone)獲取
你也許想了解具體的落地場景:
王者帶飛LeDock!開箱即用&一鍵定位分子庫+全流程自動化,3.5小時完成20萬分子對接
這樣跑COMSOL,是不是就可以發(fā)Nature了
Auto-Scale這支仙女棒如何大幅提升Virtuoso仿真效率?
1分鐘告訴你用MOE模擬200000個分子要花多少錢
LS-DYNA求解效率深度測評 │ 六種規(guī)模,本地VS云端5種不同硬件配置
揭秘20000個VCS任務(wù)背后的“搬桌子”系列故事
155個GPU!多云場景下的Amber自由能計算
怎么把需要45天的突發(fā)性Fluent仿真計算縮短到4天之內(nèi)?
5000核大規(guī)模OPC上云,效率提升53倍
提速2920倍!用AutoDock Vina對接2800萬個分子
從4天到1.75小時,如何讓Bladed仿真效率提升55倍?
從30天到17小時,如何讓HSPICE仿真效率提升42倍?
關(guān)于為應(yīng)用定義的云平臺:
當(dāng)仿真外包成為過氣網(wǎng)紅后…
和28家業(yè)界大佬排排坐是一種怎樣的體驗?
這一屆科研計算人趕DDL紅寶書:學(xué)生篇
楊洋組織的“太空營救”中, 那2小時到底發(fā)生了什么?
一次搞懂速石科技三大產(chǎn)品:FCC、FCC-E、FCP
Ansys最新CAE調(diào)研報告找到阻礙仿真效率提升的“元兇”
國內(nèi)超算發(fā)展近40年,終于遇到了一個像樣的對手
幫助CXO解惑上云成本的迷思,看這篇就夠了
花費(fèi)4小時5500美元,速石科技躋身全球超算TOP500

什么是人工智能 (AI) 軟件
它是能夠模擬智能人類行為的軟件。從更廣泛的角度來看,它是一種計算機(jī)應(yīng)用程序,可以學(xué)習(xí)數(shù)據(jù)模式和洞察力,以智能地滿足特定客戶的痛點。
人工智能包括以下內(nèi)容:
- 機(jī)器學(xué)習(xí)(ML):允許計算機(jī)收集數(shù)據(jù)并從中學(xué)習(xí)以產(chǎn)生見解。
- 深度學(xué)習(xí)(DL):ML的進(jìn)一步發(fā)展,用于檢測大量數(shù)據(jù)中的模式和趨勢并從中學(xué)習(xí)。
- 神經(jīng)網(wǎng)絡(luò):旨在學(xué)習(xí)和識別模式的互連單元,很像人腦。
- 自然語言處理(NLP):NLP 支持AI閱讀、理解和處理人類語言的能力。
- 計算機(jī)視覺:教計算機(jī)從圖像和視頻中收集和解釋有意義的數(shù)據(jù)。
這些功能被用來為不同的用例構(gòu)建人工智能軟件,其中最重要的是知識管理、虛擬輔助和自動駕駛汽車。隨著企業(yè)必須梳理大量數(shù)據(jù)以滿足客戶需求,對更快、更準(zhǔn)確的軟件解決方案的需求也在增加。
人工智能 (AI)常見軟件如下:
1.Deep Vision
Deep Vision專為個人面部分析而設(shè)計,是針對安全性,安全性和商業(yè)智能的完美AI解決方案。該軟件可有效監(jiān)視指定區(qū)域,以根據(jù)年齡,性別和其他詳細(xì)信息隨時間推移識別人員。
它使用面部人口統(tǒng)計模型來了解目標(biāo)區(qū)域內(nèi)隨時間變化的人口統(tǒng)計變化,或用于跟蹤客戶模式。此外,它還幫助廣告商和品牌與目標(biāo)受眾建立聯(lián)系,以進(jìn)行產(chǎn)品展示和廣告宣傳。該模型的創(chuàng)建是通過面部匹配來跟蹤個人,以量化訪客的訪問頻率,并幫助零售商立即找到潛在的顧客。
主要特點
- 它可以使用支持AI的技術(shù)識別視頻或圖像中的個人面孔。
- 該軟件可以通過執(zhí)行面部匹配來檢測目標(biāo)對象的位置。
- 它具有面部識別和檢測功能。該軟件只需查看人的圖像即可立即識別人的臉。
- 憑借其面部人口統(tǒng)計功能,它可以估計人們的性別和年齡。
2.Braina
它是少數(shù)支持多種語言的優(yōu)秀AI軟件之一。Braina也可以用作虛擬語音識別軟件。借助于此,可以輕松快捷地將軟件語音轉(zhuǎn)換為文本。這個以生產(chǎn)力為中心的商業(yè)智能平臺支持100多種語言。
主要特點
- Braina中集成的工具和功能使用戶可以快速完成工作。
- 它與多語言虛擬助手集成在一起。
- 該軟件為用戶提供了優(yōu)秀的成績單。另外,它還可以讀回非英語文本,以便于用戶理解。
- 其無可挑剔的語音命令使用戶可以使用自己的語音搜索,播放/暫停/停止媒體。使用此軟件,用戶可以在不費(fèi)力的情況下調(diào)整窗口大小,打開網(wǎng)站,文件夾和文件并執(zhí)行其他任務(wù)。
3.Google Cloud Machine Learning Engine
無論您是希望開展新業(yè)務(wù)還是計劃對現(xiàn)有業(yè)務(wù)進(jìn)行數(shù)字化轉(zhuǎn)型,Google AI技術(shù)和云解決方案都將幫助您取得令人難以置信的成功。Google Cloud Machine Learning Engine是用于訓(xùn)練,調(diào)整和分析模型的理想解決方案。它帶有Compute Engine,Cloud SDK,Cloud Storage和Cloud SQL。
該軟件還提供了安全耐用的對象存儲的好處。其庫和命令行工具允許用戶利用Google Cloud。此外,還有用于SQL Server,MySQL和PostgreSQL的關(guān)系數(shù)據(jù)庫。
主要特點
- Google Cloud ML Engine通過預(yù)測和監(jiān)視這些預(yù)測使用戶受益。
- 用戶可以管理其模型及其多個版本。
- 該解決方案的各個組成部分包括g-cloud,它是用于管理版本和模型的命令行工具。REST API,旨在幫助用戶進(jìn)行在線預(yù)測;和Google Cloud Platform Console(用于部署和管理模型的UI界面)。
4.Engati
使用Engati,用戶可以輕松創(chuàng)建規(guī)模和復(fù)雜程度不同的聊天機(jī)器人。它帶有150多個模板,因此個人可以快速開始使用聊天機(jī)器人。另外,該軟件還包括高級“對話流”構(gòu)建器,高端集成功能以及用于在網(wǎng)站或任何可用渠道上部署漫游器的功能。
該平臺使聊天機(jī)器人的構(gòu)建比以往更加輕松。有專門設(shè)計用于部署,構(gòu)建,分析和訓(xùn)練機(jī)器人的部分。此外,使用該軟件廣播的聊天機(jī)器人用戶信息,門戶網(wǎng)站用戶,實時聊天和廣告系列將使您受益匪淺。
主要特點
- 使用此軟件創(chuàng)建具有成本效益的聊天機(jī)器人,并輕松簡化客戶支持。
- 當(dāng)聊天代理不在線時,它提供了自動答復(fù)的好處。
- 該軟件具有自動營銷和銷售功能。使用此工具,您可以構(gòu)建聊天機(jī)器人,該聊天機(jī)器人可以作為交互式,即時的方式讓客戶獲取您的品牌詳細(xì)信息。
- 通過減輕篩選過程,它也可以減輕人事經(jīng)理的工作。該軟件能夠?qū)崟r對潛在員工進(jìn)行背景調(diào)查。
- 智能聊天機(jī)器人可幫助自動解決客戶請求。
5.Azure機(jī)器學(xué)習(xí)工作室
Azure機(jī)器學(xué)習(xí)Studio是出色的交互式編程軟件之一,最適合創(chuàng)建可用于預(yù)測分析的商業(yè)智能系統(tǒng)。它是用戶用來將對象移動到界面的高級工具。
使用此軟件,您將有機(jī)會探索在云上構(gòu)建創(chuàng)新的,基于AI的應(yīng)用程序的新技術(shù)。Azure還提供了創(chuàng)新工具,人工智能服務(wù)和可擴(kuò)展基礎(chǔ)架構(gòu)的優(yōu)勢。此外,您還將獲得構(gòu)建智能解決方案所需的資源。
主要特點
- Azure Machine Learning Studio充當(dāng)專業(yè)人員的交互式工作區(qū)。您可以借助從不同來源收集的數(shù)據(jù)來構(gòu)建預(yù)測分析模型。
- 它是一個交互式平臺,可使用數(shù)據(jù)操作和統(tǒng)計功能來轉(zhuǎn)換和分析數(shù)據(jù)。您可以輕松確定結(jié)果。
- 將分析模塊或數(shù)據(jù)集拖放到界面上,以鏈接和修改參數(shù)和功能,以設(shè)計能夠在ML Studio中運(yùn)行的合格且受過訓(xùn)練的模型。
- 借助該軟件,您可以通過編寫R腳本來準(zhǔn)備數(shù)據(jù)。
6.Tensor Flow
Tensor Flow是廣受歡迎的開源軟件,對于尋求高級數(shù)值計算工具的專業(yè)人員而言,它是一個優(yōu)秀的解決方案。它具有靈活的架構(gòu),可跨多個平臺(包括TPU,CPU和GPU)進(jìn)行計算部署。另外,它可以部署在臺式機(jī),服務(wù)器,移動設(shè)備和其他設(shè)備上。
這是Google的AI工程師和研究人員團(tuán)隊的創(chuàng)意。Tensor Flow能夠進(jìn)行深度學(xué)習(xí)和機(jī)器學(xué)習(xí)。而且,它對可在多個科學(xué)領(lǐng)域中使用的核心數(shù)學(xué)表達(dá)式提供了強(qiáng)大的支持。
它的一些核心組件包括自然語言處理,決策,聊天機(jī)器人,圖像識別,數(shù)據(jù)攝取,多語言,視覺搜索,語音識別,虛擬助手,機(jī)器學(xué)習(xí)和工作流自動化。
主要特點
- 與多維數(shù)組有關(guān)的數(shù)值計算的理想選擇
- 為有關(guān)機(jī)器學(xué)習(xí)和神經(jīng)網(wǎng)絡(luò)的概念提供出色的支持
- 使用CPU和GPU計算的用戶受益,而兩者需要一個代碼
- 用于數(shù)據(jù)集和各種機(jī)器的高度可擴(kuò)展的計算
7.Cortana
像Google Now和Siri一樣,Cortana是一個智能的個人助理,可以幫助用戶啟動應(yīng)用程序,安排約會以及許多其他虛擬任務(wù)。它還能夠調(diào)整設(shè)備設(shè)置,例如將Wi-Fi切換為關(guān)閉和打開模式。該工具還可以回答您的查詢,設(shè)置提醒,開燈,在線訂購比薩等。
主要特點
- 它在Bing搜索引擎上運(yùn)行。
- 它與Xbox OS,iOS,Windows和Android兼容。
- 該平臺支持多種語言,包括日語,英語,法語,葡萄牙語,意大利語,德語,西班牙語和中文。
- 使用其語音輸入功能,您可以管理和安排會議/重要任務(wù),查找定義,事實等。
- 該工具甚至可以通過語音命令打開系統(tǒng)上的應(yīng)用程序。
8.IBM沃森
這是一個基于AI的計算機(jī)系統(tǒng),旨在回答用戶的問題。IBM Watson與認(rèn)知計算集成在一起-包括推理,機(jī)器學(xué)習(xí),自然語言處理,人工智能等技術(shù)的融合。該工具以IBM首任首席執(zhí)行官Thomas J. Watson爵士的名字命名,可將人工智能集成到各種業(yè)務(wù)流程中。它有助于提高組織的生產(chǎn)率和效率,從而可以獲得更好的結(jié)果。
通常,業(yè)務(wù)數(shù)據(jù)采用非結(jié)構(gòu)化的形式,例如語音數(shù)據(jù),段落等。借助IBM Watson,專業(yè)人員可以系統(tǒng)地整理和組織非結(jié)構(gòu)化數(shù)據(jù),以生成所需的信息。IBM Watson的處理速度約為80 teraflops,是人類回答問題能力的兩倍。
主要特點
- 使用此工具,您將完全控制基本任務(wù)。它可以通過保護(hù)IP地址,維護(hù)數(shù)據(jù)所有權(quán)和保護(hù)數(shù)據(jù)洞察力來處理所有這一切。
- 該軟件經(jīng)過培訓(xùn),可以重新構(gòu)想用戶的工作流程,而不管他們的工作領(lǐng)域如何。它是運(yùn)輸,醫(yī)療保健,金融,教育(包括其他領(lǐng)域)的理想選擇。
- 它對幾乎所有行業(yè)和企業(yè)都有深入的了解。該軟件可以幫助您做出更快更好的決策。
- IBM甚至重視數(shù)據(jù)的最小單位。如果您的數(shù)據(jù)量很小,則可以分析并確定可能的結(jié)果。
- 無需集成任何其他工具,它就可以使用大量數(shù)據(jù)。通過使用它,您可以輕松地從多個來源訪問所需的數(shù)據(jù)。
9.Infosys Nia
Infosys Nia是一款高度評價的商業(yè)智能軟件,可以從舊版系統(tǒng),人員和流程中收集信息。它將數(shù)據(jù)聚合到一個知識庫中,并自動執(zhí)行IT流程和業(yè)務(wù)任務(wù)。該軟件旨在減少人工工作,并找到需要想象力,創(chuàng)造力和激情的客戶問題的解決方案。
用戶可以利用該平臺來獲得深入的見解,增強(qiáng)的知識以及探索機(jī)會,以簡化,優(yōu)化和自動化復(fù)雜的組織流程。
主要特點
- 它有助于增強(qiáng)流程和系統(tǒng),以增強(qiáng)組織及其員工的能力。
- 它包括一個高級的對話UI。
- 該工具具有用于編程和重復(fù)任務(wù)的自動化功能。
- 它是結(jié)合認(rèn)知自動化,RPA和預(yù)測自動化的自動化平臺之一。
- 它可以捕獲,處理和重用知識,以更好地開展業(yè)務(wù)。
- 該平臺還能夠為用戶提供數(shù)據(jù)分析。
- 它也可以用作機(jī)器學(xué)習(xí)工具。
10.Playment
它是一個數(shù)據(jù)標(biāo)記平臺,可以為機(jī)器人模型大規(guī)模生成訓(xùn)練數(shù)據(jù)。Playment增強(qiáng)了處理無人機(jī),制圖,自動駕駛和類似空間的業(yè)務(wù)。
該工具已由CYNGN,Drive AI和Starsky Robotics等多家知名研究機(jī)構(gòu)和組織選擇。
主要特點
- 支付具有AI和人類智能的獨(dú)特組合。它可用于映射輸出質(zhì)量。
- 它是一種高質(zhì)量的工具,能夠以100%的準(zhǔn)確性組織多個類別的圖像。
- 該平臺與競爭對手分析和產(chǎn)品比較功能集成在一起。
- 企業(yè)使用它來使用戶意識到可以帶來良好結(jié)果的事物以及可能被證明對他們的業(yè)務(wù)致命的事物。
- 該工具附帶一個圖像注釋套件,允許用戶構(gòu)建對計算機(jī)視覺技術(shù)有用的數(shù)據(jù)集。
11. PyTorch
PyTorch是一個開源的機(jī)器學(xué)習(xí)庫,基于Torch,用于自然語言處理等應(yīng)用程序。
PyTorch的前身是Torch,其底層和Torch框架一樣,但是使用Python重新寫了很多內(nèi)容,不僅更加靈活,支持動態(tài)圖,而且提供了Python接口。它是由Torch7團(tuán)隊開發(fā),是一個以Python優(yōu)先的深度學(xué)習(xí)框架,不僅能夠?qū)崿F(xiàn)強(qiáng)大的GPU加速,同時還支持動態(tài)神經(jīng)網(wǎng)絡(luò)。
PyTorch既可以看作加入了GPU支持的numpy,同時也可以看成一個擁有自動求導(dǎo)功能的強(qiáng)大的深度神經(jīng)網(wǎng)絡(luò)。
2022年9月,扎克伯格親自宣布,PyTorch 基金會已新鮮成立,并歸入 Linux 基金會旗下
主要特點
- PyTorch是相當(dāng)簡潔且高效快速的框架
- 設(shè)計追求最少的封裝
- 設(shè)計符合人類思維,它讓用戶盡可能地專注于實現(xiàn)自己的想法
- 與google的Tensorflow類似,F(xiàn)AIR的支持足以確保PyTorch獲得持續(xù)的開發(fā)更新
- PyTorch作者親自維護(hù)的論壇 供用戶交流和求教問題
12.H20
它聲稱任何人都可以利用機(jī)器學(xué)習(xí)和預(yù)測分析的力量來解決業(yè)務(wù)難題。可以用于預(yù)測建模、保險分析、風(fēng)險和欺詐分析、醫(yī)療保健、廣告技術(shù)和客戶情報。
它有兩種開源版本: Sparking Water 版和標(biāo)準(zhǔn)版 H2O ,被集成在 Apache Spark 中。也有付費(fèi)的企業(yè)用戶支持。
13.OpenNN
作為一個為開發(fā)者和科研人員設(shè)計的具有高級理解力的人工智能,OpenNN 是一個實現(xiàn)神經(jīng)網(wǎng)絡(luò)算法的 c++ 編程庫。
其關(guān)鍵特性包括深度的架構(gòu)和快速的性能。其網(wǎng)站上可以查到豐富的文檔,包括一個解釋了神經(jīng)網(wǎng)絡(luò)的基本知識的入門教程。OpenNN 的付費(fèi)支持由一家從事預(yù)測分析的西班牙公司 Artelnics 提供。
14.NuPIC
由 Numenta 公司管理的 NuPIC 是一個基于分層暫時記憶Hierarchical Temporal Memory,HTM理論的開源人工智能項目。
從本質(zhì)上講,HTM 試圖創(chuàng)建一個計算機(jī)系統(tǒng)來模仿人類大腦皮層。他們的目標(biāo)是創(chuàng)造一個 “在許多認(rèn)知任務(wù)上接近或者超越人類認(rèn)知能力” 的機(jī)器。
除了開源許可,Numenta 還提供 NuPic 的商業(yè)許可協(xié)議,并且它還提供技術(shù)專利的許可證。
15.Oryx 2
構(gòu)建在 Apache Spark 和 Kafka 之上的 Oryx 2 是一個專門針對大規(guī)模機(jī)器學(xué)習(xí)的應(yīng)用程序開發(fā)框架。它采用一個獨(dú)特的三層 λ 架構(gòu)。
開發(fā)者可以使用 Orys 2 創(chuàng)建新的應(yīng)用程序,另外它還擁有一些預(yù)先構(gòu)建的應(yīng)用程序可以用于常見的大數(shù)據(jù)任務(wù)比如協(xié)同過濾、分類、回歸和聚類。大數(shù)據(jù)工具供應(yīng)商 Cloudera 創(chuàng)造了最初的 Oryx 1 項目并且一直積極參與持續(xù)發(fā)展。
16.OpenCyc
由 Cycorp 公司開發(fā)的 OpenCyc 提供了對 Cyc 知識庫的訪問和常識推理引擎。它擁有超過 239,000 個條目,大約 2,093,000 個三元組和大約 69,000 owl:這是一種類似于鏈接到外部語義庫的命名空間。
它在富領(lǐng)域模型、語義數(shù)據(jù)集成、文本理解、特殊領(lǐng)域的專家系統(tǒng)和游戲 AI 中有著良好的應(yīng)用。
該公司還提供另外兩個版本的 Cyc:一個可免費(fèi)的用于科研但是不開源,和一個提供給企業(yè)的但是需要付費(fèi)。
17.SystenML
最初由 IBM 開發(fā), SystemML 現(xiàn)在是一個 Apache 大數(shù)據(jù)項目。
它提供了一個高度可伸縮的平臺,可以實現(xiàn)高等數(shù)學(xué)運(yùn)算,并且它的算法用 R 或一種類似 python 的語法寫成。
企業(yè)已經(jīng)在使用它來跟蹤汽車維修客戶服務(wù)、規(guī)劃機(jī)場交通和連接社會媒體數(shù)據(jù)與銀行客戶。它可以在 Spark 或 Hadoop 上運(yùn)行。
18.Torch
Torch 把自己描述為:“一個優(yōu)先使用 GPU 的,擁有機(jī)器學(xué)習(xí)算法廣泛支持的科學(xué)計算框架”,特點是靈活性和速度。
另外,Torch可以很容易的通過軟件包用于計算機(jī)視覺、機(jī)器學(xué)習(xí)、信號處理、并行處理、視頻、圖像、音頻和網(wǎng)絡(luò)等方面。依賴一個叫做 LuaJIT 的腳本語言,而 LuaJIT 是基于 Lua 的。
19.MLlib
MLlib 是 Spark 的可擴(kuò)展機(jī)器學(xué)習(xí)庫。它集成了 Hadoop 并可以與 NumPy 和 R 進(jìn)行交互操作。
它包括了許多機(jī)器學(xué)習(xí)算法如分類、決策樹、推薦、主題建模、集群、功能轉(zhuǎn)換、模型評價、生存分析、ML 管道架構(gòu)、ML 持久、頻繁項集和序列模式挖掘、分布式線性代數(shù)和統(tǒng)計。
20.Mahout
它是 Apache 基金會項目,Mahout 是一個開源機(jī)器學(xué)習(xí)框架。
主要特點:
- 一個構(gòu)建可擴(kuò)展算法的編程環(huán)境 。
- 像 Spark 和 H2O 一樣的預(yù)制算法工具
- 一個叫 Samsara 的矢量數(shù)學(xué)實驗環(huán)境 。
目前使用 Mahout 的公司有 埃森哲咨詢公司、Adobe、英特爾、領(lǐng)英、Twitter、Foursquare、雅虎和其他許多公司。
21.Deeplearning4j
Deeplearning4j 是一個 java 虛擬機(jī)(JVM)的開源深度學(xué)習(xí)庫。它運(yùn)行在分布式環(huán)境并且集成在Apache Spark 和 Hadoop 中。這使它可以配置深度神經(jīng)網(wǎng)絡(luò),并且它與Scala 、 Java和 其他 JVM 語言兼容。
22.Caffe
Caffe是由賈揚(yáng)清在加州大學(xué)伯克利分校讀博時創(chuàng)造的, 是一個基于表達(dá)體系結(jié)構(gòu)和可擴(kuò)展代碼的深度學(xué)習(xí)框架。使它聲名鵲起的是速度,這使它非常受到研究人員和企業(yè)用戶的歡迎。
根據(jù)其網(wǎng)站所言,它可以在一天之內(nèi)只用一個 NVIDIA K40 GPU 處理 6000 萬多個圖像。它是由伯克利視野和學(xué)習(xí)中心(BVLC)管理的,并且由 NVIDIA 和亞馬遜等公司資助來支持它的發(fā)展。
- END -
我們有個AI研發(fā)云平臺
集成多種AI應(yīng)用,大量任務(wù)多節(jié)點并行
應(yīng)對短時間爆發(fā)性需求,連網(wǎng)即用
跑任務(wù)快,原來幾個月甚至幾年,現(xiàn)在只需幾小時
5分鐘快速上手,拖拉點選可視化界面,無需代碼
支持高級用戶直接在云端創(chuàng)建集群?
掃碼免費(fèi)試用,送200元體驗金,入股不虧~

更多電子書歡迎掃碼關(guān)注小F(ID:iamfastone)獲取
你也許想了解具體的落地場景:
王者帶飛LeDock!開箱即用&一鍵定位分子庫+全流程自動化,3.5小時完成20萬分子對接
這樣跑COMSOL,是不是就可以發(fā)Nature了
Auto-Scale這支仙女棒如何大幅提升Virtuoso仿真效率?
1分鐘告訴你用MOE模擬200000個分子要花多少錢
LS-DYNA求解效率深度測評 │ 六種規(guī)模,本地VS云端5種不同硬件配置
揭秘20000個VCS任務(wù)背后的“搬桌子”系列故事
155個GPU!多云場景下的Amber自由能計算
怎么把需要45天的突發(fā)性Fluent仿真計算縮短到4天之內(nèi)?
5000核大規(guī)模OPC上云,效率提升53倍
提速2920倍!用AutoDock Vina對接2800萬個分子
從4天到1.75小時,如何讓Bladed仿真效率提升55倍?
從30天到17小時,如何讓HSPICE仿真效率提升42倍?
關(guān)于為應(yīng)用定義的云平臺:
當(dāng)仿真外包成為過氣網(wǎng)紅后…
和28家業(yè)界大佬排排坐是一種怎樣的體驗?
這一屆科研計算人趕DDL紅寶書:學(xué)生篇
楊洋組織的“太空營救”中, 那2小時到底發(fā)生了什么?
一次搞懂速石科技三大產(chǎn)品:FCC、FCC-E、FCP
Ansys最新CAE調(diào)研報告找到阻礙仿真效率提升的“元兇”
國內(nèi)超算發(fā)展近40年,終于遇到了一個像樣的對手
幫助CXO解惑上云成本的迷思,看這篇就夠了
花費(fèi)4小時5500美元,速石科技躋身全球超算TOP500