
在上一篇生信云實(shí)證《提速2920倍!用AutoDock Vina對(duì)接2800萬個(gè)分子》里,我們基于不同用戶策略,調(diào)用10萬核CPU資源,幫用戶進(jìn)行了2800萬量級(jí)的大規(guī)模分子對(duì)接,將運(yùn)算效率提高2920倍。

對(duì)藥物分子的虛擬篩選,僅僅實(shí)現(xiàn)分子對(duì)接是不夠的,往往會(huì)面臨一個(gè)問題就是藥物分子活性的評(píng)價(jià)。許多藥物和其它生物分子的活性都是通過與受體大分子之間的相互作用表現(xiàn)出來的,是動(dòng)態(tài)的。
受體和配體之間結(jié)合自由能(Binding Afinity)評(píng)價(jià)是基于結(jié)構(gòu)的計(jì)算機(jī)輔助藥物分子設(shè)計(jì)的核心問題。
基于分子動(dòng)力學(xué)(Molecular Dynamics, MD)模擬的煉金術(shù)自由能(Alchemical Free Energy,AFE)計(jì)算是提高我們對(duì)各種生物過程的理解以及加快多種疾病的藥物設(shè)計(jì)和優(yōu)化的關(guān)鍵工具。
MD模擬實(shí)驗(yàn)數(shù)據(jù)量大,計(jì)算周期長,常用軟件包括Amber、NAMD、GROMACS、Schr?dinger等等。GPU的并行處理技術(shù)能大大加速計(jì)算效率,所以很多MD模擬軟件都開始支持GPU。

GROMACS作為一款開源軟件,完全免費(fèi),但其成熟版本對(duì)于GPU的支持并不理想,教程相對(duì)少,對(duì)用戶的要求比較高。
Schr?dinger是商用軟件,功能全面,GPU支持很好,但License是按使用核數(shù)計(jì)算的,價(jià)格相對(duì)昂貴。
Amber軟件包包括兩個(gè)部分:AmberTools和Amber。
AmberTools可以在Amber官網(wǎng)免費(fèi)下載和使用,Tools中包含了Amber絕大部分模塊,但不支持PMEMD和GPU加速。
Amber是收費(fèi)的,從Amber11開始支持GPU加速仿真,Amber18開始支持GPU計(jì)算自由能,且教程齊全易操作,不限制CORE的使用數(shù)量。2020年4月,已經(jīng)更新到Amber20版本。
學(xué)術(shù)/非營利組織/政府:500美元
企業(yè):新Amber20用戶 20000美元(原Amber18用戶 15000美元)
今天實(shí)證的主角是Amber,有幾個(gè)重點(diǎn)我們先說為敬:
第一、不同GPU型號(hào)價(jià)格差異極大,對(duì)Amber自由能計(jì)算的適配度和運(yùn)算效率也不同,如何為用戶選擇最匹配的資源類型;
第二、用戶對(duì)GPU的需求量比較大,而不同云廠商提供的可用GPU資源數(shù)量不確定,價(jià)格差異也很大,可能需要跨多家云廠商調(diào)度,如何實(shí)現(xiàn)?同時(shí),盡可能降低成本;
第三、用戶使用的Amber18版本,根據(jù)我們的經(jīng)驗(yàn),在使用GPU計(jì)算時(shí)存在10%-15%的失敗概率。一旦任務(wù)失敗,需要調(diào)度CPU重新計(jì)算,能否及時(shí)且自動(dòng)地處理失敗任務(wù),將極大影響運(yùn)算周期。
用戶需求
某高校研究所對(duì)一組任務(wù)使用Amber18進(jìn)行自由能計(jì)算,使用本地48核CPU資源需要12小時(shí),而使用1張GPU卡運(yùn)算該組任務(wù)只需3小時(shí)。
該研究所目前面臨16008個(gè)任務(wù)需要使用Amber18進(jìn)行自由能計(jì)算,負(fù)責(zé)人根據(jù)以往數(shù)據(jù)估算使用本地CPU資源可能要1年以上才能完成任務(wù),使用單個(gè)GPU需要至少4個(gè)月,周期過長,課題等不了。
因此,他們迫切希望通過使用云上資源,尤其是GPU資源來快速補(bǔ)充本地算力的不足,更快完成任務(wù)。
實(shí)證目標(biāo)
1、Amber自由能計(jì)算能否在云端有效運(yùn)行?
2、fastone是否能為用戶選擇合適的GPU實(shí)例類型?
3、fastone平臺(tái)是否能在短時(shí)間內(nèi)獲取足夠的GPU資源,大幅度縮短項(xiàng)目周期?
4、Amber18版本運(yùn)行GPU的失敗概率問題,fastone平臺(tái)是否能有效處理?
實(shí)證參數(shù)
平臺(tái):
fastone企業(yè)版產(chǎn)品
應(yīng)用:
Amber18
操作系統(tǒng):
CentOS 7.5
適用場(chǎng)景:
基于分子動(dòng)力學(xué)模擬的自由能預(yù)測(cè)
云端硬件配置:
NVIDIA Tesla K80
NVIDIA Tesla V100
調(diào)度器:
Slurm
技術(shù)架構(gòu)圖:
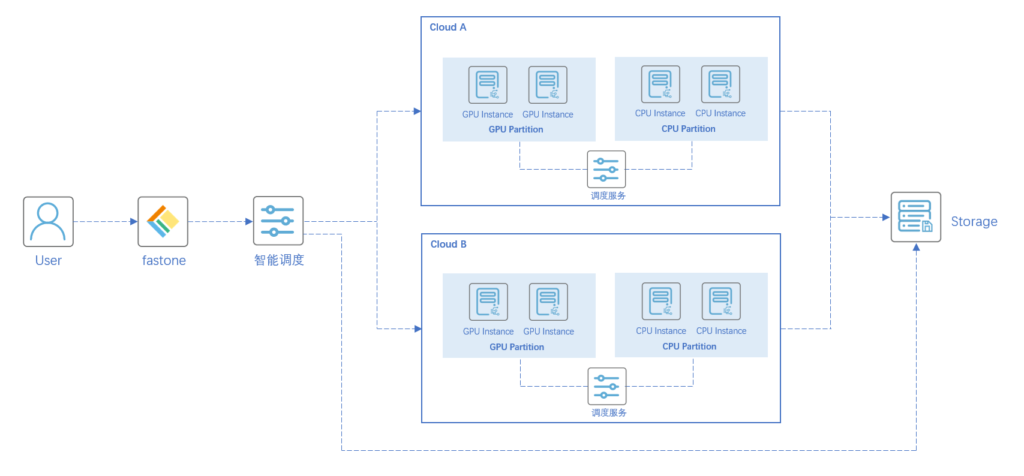
實(shí)證場(chǎng)景一
GPU實(shí)例類型驗(yàn)證—120個(gè)任務(wù)
新版的GPU資源,運(yùn)行速度快,但是價(jià)格高。
老版的GPU資源,價(jià)格是便宜了,但是運(yùn)行速度也慢。
老機(jī)型就一定劃算嗎?這可不一定。
結(jié)論:
1、無論是從時(shí)間效率還是成本的角度,都應(yīng)選擇更新型的NVIDIA Tesla V100;
2、在云端運(yùn)算相同的Amber18任務(wù)時(shí),NVIDIA Tesla K80的耗時(shí)是NVIDIA Tesla V100的約5-6倍,從時(shí)間效率的角度,V100明顯占優(yōu);
3、NVIDIA Tesla K80云端GPU實(shí)例的定價(jià)約為NVIDIA Tesla V100云端GPU實(shí)例的不到三分之一(某公有云廠商官網(wǎng)上單個(gè)K80的按需價(jià)格為0.9美元/小時(shí),V100則為3.06美元/小時(shí)),綜合計(jì)算得出V100的性價(jià)比是K80的約1.4-1.8倍。
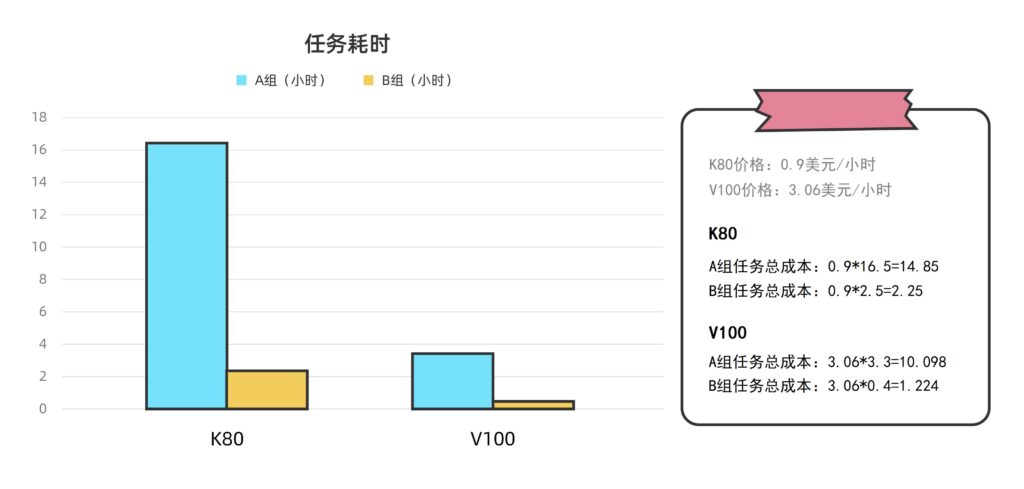
實(shí)證過程:
1、云端調(diào)度1個(gè)NVIDIA Tesla K80云端GPU實(shí)例運(yùn)算A組Amber任務(wù),耗時(shí)16.5小時(shí);
2、云端調(diào)度1個(gè)NVIDIA Tesla K80云端GPU實(shí)例運(yùn)算B組Amber任務(wù),耗時(shí)2.5小時(shí);
3、云端調(diào)度1個(gè)NVIDIA Tesla V100云端GPU實(shí)例運(yùn)算A組Amber任務(wù),耗時(shí)3.3小時(shí);
4、云端調(diào)度1個(gè)NVIDIA Tesla V100云端GPU實(shí)例運(yùn)算B組Amber任務(wù),耗時(shí)0.4小時(shí)。
實(shí)證場(chǎng)景二
大規(guī)模GPU多云場(chǎng)景驗(yàn)證—16008個(gè)任務(wù)
結(jié)論:
fastone平臺(tái)根據(jù)用戶任務(wù)需要和特性,跨兩家公有云廠商,智能自動(dòng)化調(diào)度云端GPU/CPU異構(gòu)資源,包括155個(gè)NVIDIA Tesla V100和部分CPU資源,將運(yùn)算16008個(gè)Amber任務(wù)的耗時(shí)從單GPU的4個(gè)月縮短到20小時(shí)。
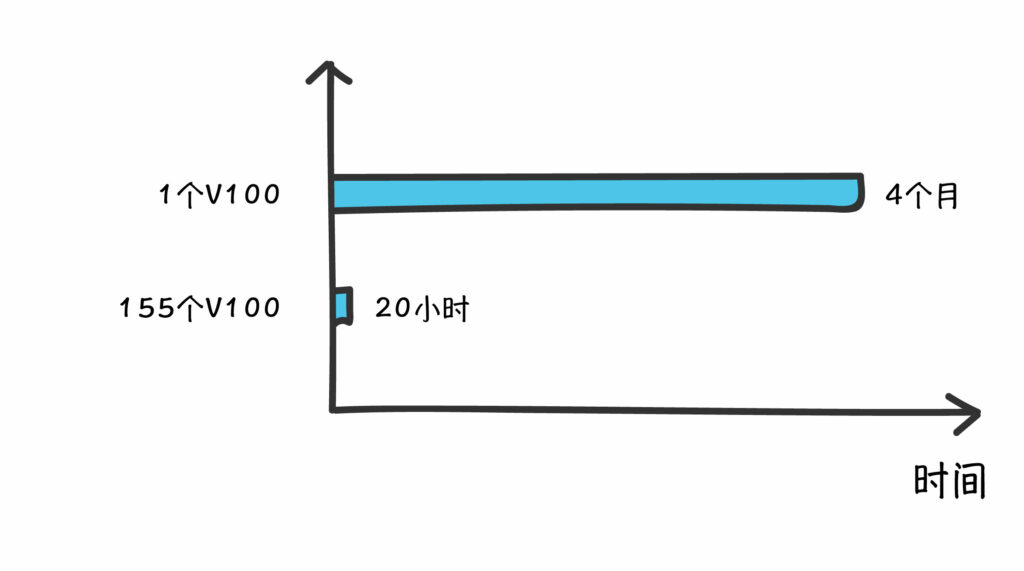
1、怎么通過Auto-Scale功能提高GPU資源的利用率?
用戶的Amber任務(wù)運(yùn)算時(shí)存在依從機(jī)制,即每12個(gè)任務(wù)中包含1個(gè)主任務(wù),只有當(dāng)主任務(wù)運(yùn)行結(jié)束后,其他11個(gè)任務(wù)才能開始并行運(yùn)算。
在本場(chǎng)景中,由于任務(wù)數(shù)量高達(dá)16008個(gè),這就意味著有1334個(gè)主任務(wù)需要率先跑完。
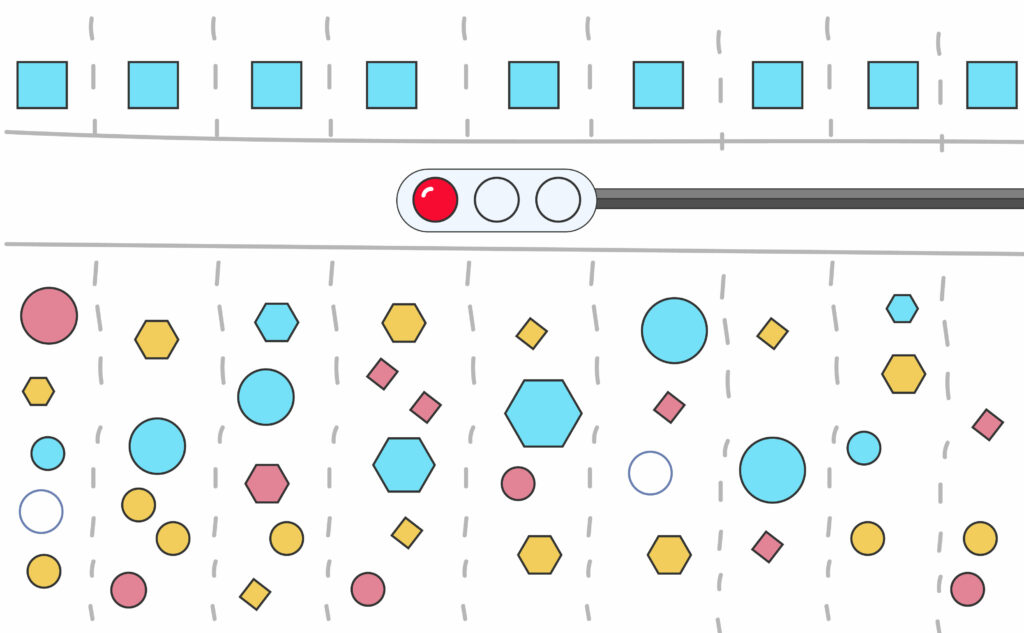
本次實(shí)證中:
第一,任務(wù)有先后,所以需要先跑主任務(wù),在每個(gè)主任務(wù)完成之后自動(dòng)調(diào)度資源并行運(yùn)算其他11個(gè)任務(wù);
第二,不同任務(wù)完成時(shí)間可能不同,對(duì)資源的需求量可能時(shí)高時(shí)低有波動(dòng),最終結(jié)束關(guān)機(jī)時(shí)間也不同。
fastone平臺(tái)使用Slurm調(diào)度器按順序調(diào)度任務(wù)排隊(duì),Auto-Scale功能可自動(dòng)監(jiān)控用戶提交的任務(wù)數(shù)量和資源的需求,動(dòng)態(tài)按需地開啟與關(guān)閉所需算力資源,在提升效率的同時(shí)有效降低成本。
關(guān)鍵是,一切都是自動(dòng)的。
隨任務(wù)需要自動(dòng)化開機(jī)和關(guān)機(jī)到底有多省錢省心,誰用誰知道。
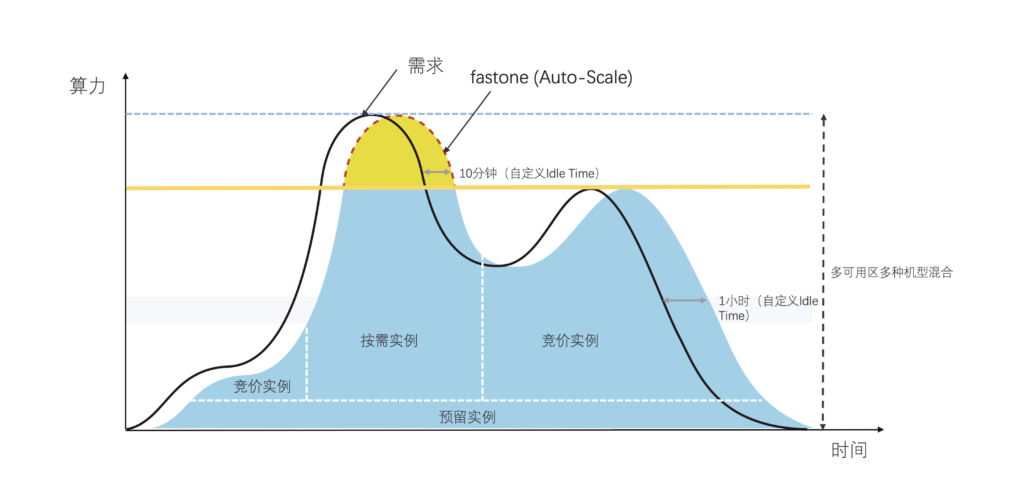
用戶還可根據(jù)自己需求,設(shè)置自動(dòng)化調(diào)度集群規(guī)模上下限,相比手動(dòng)模式能夠節(jié)省大量時(shí)間與成本。
調(diào)度器是干嘛的,為什么大規(guī)模集群需要用到調(diào)度器,有哪些流派,不同調(diào)度器之間區(qū)別是什么等等問題可以參考億萬打工人的夢(mèng):16萬個(gè)CPU隨你用
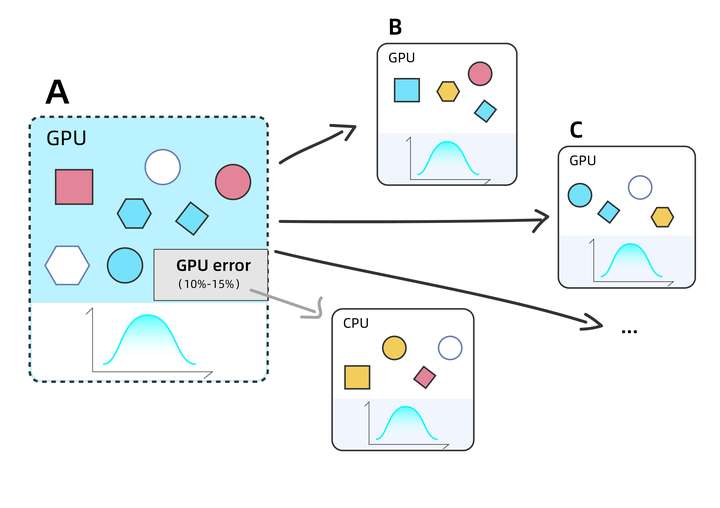
2、任務(wù)用GPU運(yùn)算失敗,怎么及時(shí)用CPU自動(dòng)重算?
Amber18在使用GPU時(shí)計(jì)算時(shí)有10-15%概率失敗,需要及時(shí)調(diào)度CPU資源重新計(jì)算,這里會(huì)涉及到一個(gè)問題:錯(cuò)誤的任務(wù)能否及時(shí)重新用CPU運(yùn)行。(注:該問題已在Amber20中修復(fù))
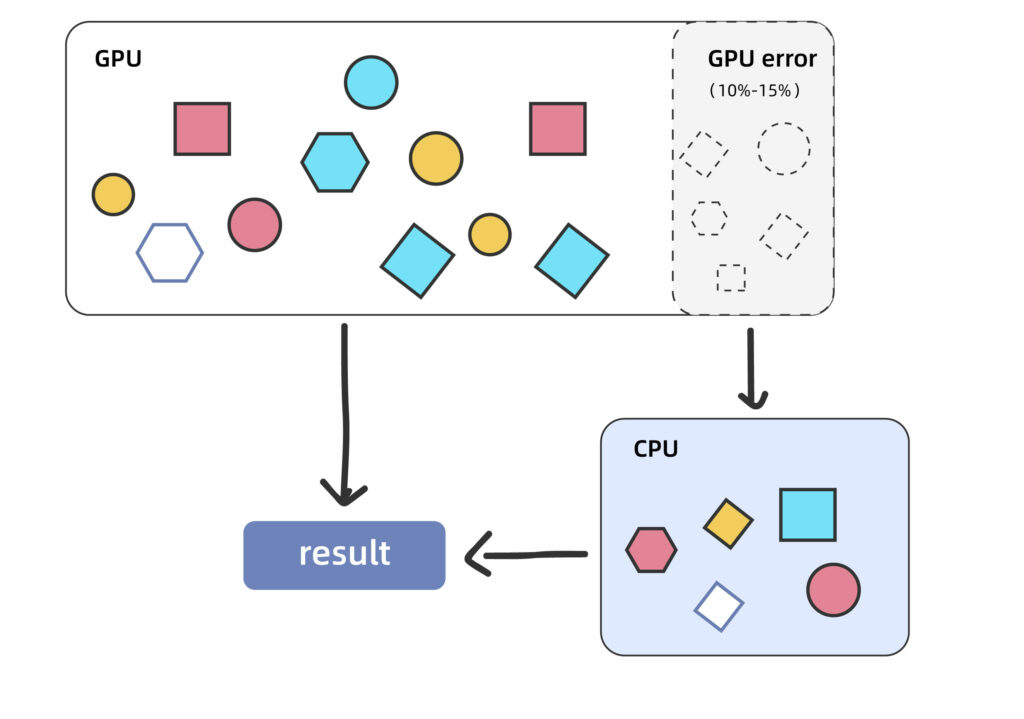
跟上一點(diǎn)一樣,自動(dòng)化還是手動(dòng)的部署差別非常大。
失敗任務(wù)自動(dòng)跳出來重新運(yùn)行,嗯,就是這么乖巧。
自動(dòng)化模式和手動(dòng)模式到底多大差別,多省錢省心可以看這篇:EDA云實(shí)證Vol.1:從30天到17小時(shí),如何讓HSPICE仿真效率提升42倍?
本次實(shí)證中:
由于任務(wù)總數(shù)高達(dá)16008個(gè),全部使用GPU計(jì)算,預(yù)計(jì)將會(huì)有1600-2400個(gè)任務(wù)算錯(cuò),對(duì)自動(dòng)化調(diào)度CPU資源的響應(yīng)速度和規(guī)模提出了很高的要求。
fastone平臺(tái)提供的智能調(diào)度策略,能在使用GPU資源計(jì)算失敗時(shí),自動(dòng)定位任務(wù)并按需開啟CPU資源,對(duì)該任務(wù)重新進(jìn)行計(jì)算,直到計(jì)算完成為止。
3、GPU資源的多云調(diào)度,如何兼顧成本和效率,最大化用戶利益?
云上的GPU可用資源有限,155個(gè)NVIDIA Tesla V100不是一個(gè)小數(shù)目,單個(gè)公有云廠商單區(qū)域資源未必能夠隨時(shí)滿足需求。
本次實(shí)證中:
第一,涉及到跨兩家公有云廠商之間的資源調(diào)度;
第二,GPU資源的在不同云廠商之間有著顯著的差異,而且往往資源多的售價(jià)高,便宜的資源少,怎么兼顧成本和效率。
以各大公有云廠商在北京地區(qū)的GPU實(shí)例(V100)按需價(jià)格為例,最高價(jià)格超過最低價(jià)2倍。
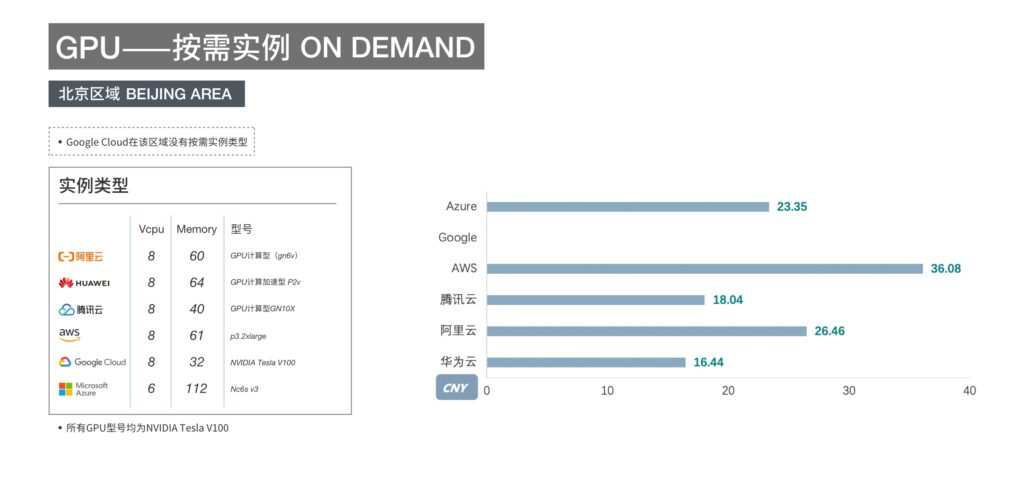
關(guān)于不同云廠商之間的價(jià)格比較和SPOT競(jìng)價(jià)實(shí)例到底能有多便宜,可以看這篇:【2020新版】六家云廠商價(jià)格比較:AWS/阿里云/Azure/Google Cloud/華為云/騰訊云
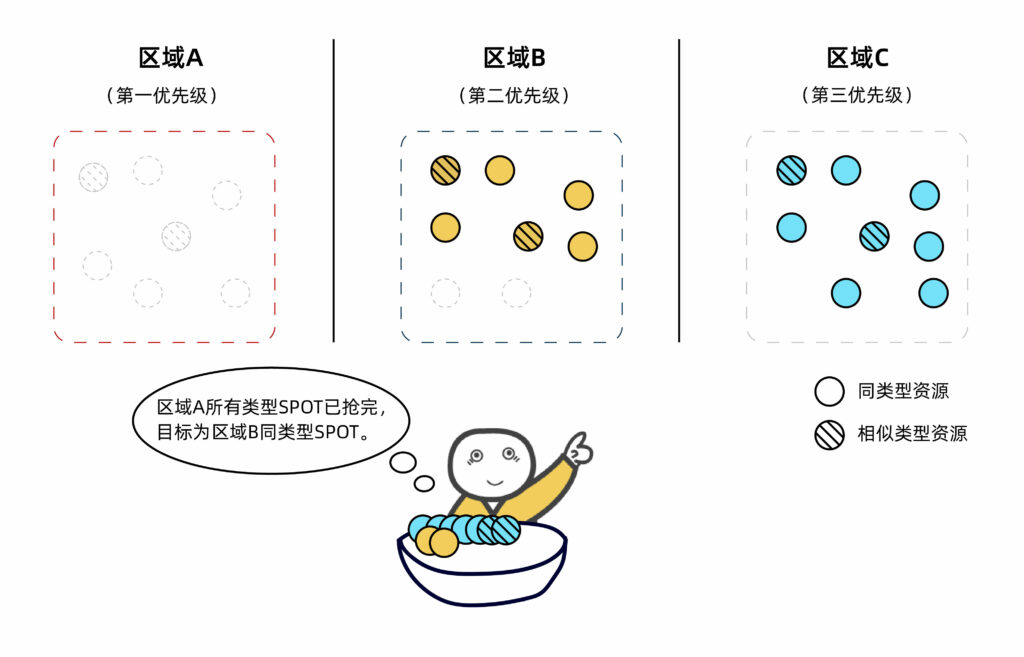
fastone平臺(tái)可綜合考量用戶對(duì)完成任務(wù)所需時(shí)間和成本的具體要求,在多個(gè)云廠商的資源之間選擇最適配的組合方案,為用戶跨地區(qū)、跨云廠商調(diào)度所需資源。
下圖場(chǎng)景是出于成本優(yōu)化目的,我們?yōu)橛脩糇詣?dòng)調(diào)度本區(qū)域及其他區(qū)域的目標(biāo)類型或相似類型SPOT實(shí)例資源。
具體看這篇:生信云實(shí)證Vol.3:提速2920倍!用AutoDock Vina對(duì)接2800萬個(gè)分子
本次實(shí)證,fastone平臺(tái)完美解決了以上三個(gè)挑戰(zhàn):
第一,自動(dòng)監(jiān)控用戶提交的任務(wù)數(shù)量和資源的需求,動(dòng)態(tài)按需地自動(dòng)化開啟與關(guān)閉所需算力資源,提高GPU資源利用率;
第二,在GPU資源計(jì)算失敗時(shí),自動(dòng)定位任務(wù)并按需開啟CPU資源,對(duì)該任務(wù)重新進(jìn)行計(jì)算,直到計(jì)算完成為止;
第三,在多個(gè)云廠商的資源之間選擇最適配的組合方案,為用戶跨地區(qū)、跨云廠商調(diào)度所需GPU資源。
實(shí)證小結(jié)
1、Amber任務(wù)能夠在云端有效運(yùn)行;
2、fastone為用戶任務(wù)推薦最適配的GPU資源類型;
3、fastone平臺(tái)能夠在短時(shí)間內(nèi)跨區(qū)域,跨云廠商獲取足夠的GPU資源,滿足用戶短時(shí)間算力需求,大幅度縮短項(xiàng)目周期;
4、針對(duì)Amber18版本運(yùn)行GPU任務(wù)失敗概率問題,fastone平臺(tái)可自動(dòng)調(diào)度CPU資源重新計(jì)算,降低。
本次生信行業(yè)Cloud HPC實(shí)證系列Vol.6就到這里了。
在下一期的生信云實(shí)證中,我們聊MOE。
請(qǐng)保持關(guān)注哦!
- END -
我們有個(gè)【在線體驗(yàn)版】
集成多種應(yīng)用,大量任務(wù)多節(jié)點(diǎn)并行
應(yīng)對(duì)短時(shí)間爆發(fā)性需求,連網(wǎng)即用
跑任務(wù)快,原來幾個(gè)月甚至幾年,現(xiàn)在只需幾小時(shí)
5分鐘快速上手,拖拉點(diǎn)選可視化界面,無需代碼
支持高級(jí)用戶直接在云端創(chuàng)建集群
掃碼免費(fèi)試用,送200元體驗(yàn)金,入股不虧~

2020年新版《六大云廠商資源價(jià)格對(duì)比工具包》
添加小F微信(ID: imfastone)獲取
你也許想了解具體的落地場(chǎng)景:
怎么把需要45天的突發(fā)性Fluent仿真計(jì)算縮短到4天之內(nèi)?
EDA云實(shí)證Vol.4 ,5000核大規(guī)模OPC上云,效率提升53倍
提速2920倍!用AutoDock Vina對(duì)接2800萬個(gè)分子
從4天到1.75小時(shí),如何讓Bladed仿真效率提升55倍?
從30天到17小時(shí),如何讓HSPICE仿真效率提升42倍?
關(guān)于云端高性能計(jì)算平臺(tái):
國內(nèi)超算發(fā)展近40年,終于遇到了一個(gè)像樣的對(duì)手






